Get Marketing Insights First
Subscribe to receive content strategies, SEO tips, and traffic insights delivered straight to your inbox.
DeepSeek’s cache relies on exact prefix matching. Any tiny difference breaks the cache. Therefore, split your prompt structure into three zones:
Intercepts identical idempotent requests, reducing ineffective calls by ~18%.
import httpx
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.deepseek.com",
# Enable local cache directory and TTL (e.g., 15 min)
cache_dir="/path/to/your/cache_dir",
cache_ttl=900,
# Inject connection pool enabled HTTP client
http_client=httpx.Client(
pool_limits=httpx.Limits(
max_connections=100,
max_keepalive_connections=20
)
)
)Deploy a dedicated Redis instance with allkeys-lru eviction policy. Set graded TTLs for short‑lived data. Cache key format: deepseek:response:{md5(prompt+params)} to ensure consistent parameter serialization.
model, temperature, top_p, etc. Enabling/disabling enable_thinking also creates different caches.Cache-Control: public, max-age=3600 to allow gateway/CDN caching.Always check the usage field in API responses:
prompt_cache_hit_tokens – tokens served from cache (money saved).prompt_cache_miss_tokens – tokens not in cache (standard input cost).prompt_cache_hit_tokens / (prompt_cache_hit_tokens + prompt_cache_miss_tokens).| Metric | Target | Description |
|---|---|---|
| Effective cache hit rate (token‑level) | >80% | In long sessions or high‑frequency scenarios, aim for 85%+. |
| Average response time | <500ms | Cache hits reduce server latency to ~2ms. |
| Cost per session | Significant reduction | Compared to no caching, expect >90% reduction. |
| Cache size (client side) | Monitor continuously | Watch local & Redis cache capacity; adjust eviction policies. |
| Cache hit rate (request level) | — | Proportion of requests served from cache. |
enable_thinking=True changes the inference path and prevents cache reuse. When using streaming responses, ensure stream_options parameters are always identical.flowchart LR
A[API Request] --> B{Prefix Matching}
B -->|Exact Match| C[Cache Hit]
B -->|Mismatch| D[Cache Miss]
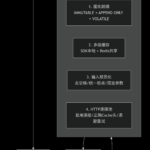
subgraph Strategy[四步优化策略]
S1[1. 固化前缀<br/>IMMUTABLE + APPEND-ONLY + VOLATILE]
S2[2. 多级缓存<br/>SDK本地 + Redis共享]
S3[3. 输入规范化<br/>去空格/统一标点/固定参数]
S4[4. HTTP连接池<br/>复用连接/正确Cache头/退避重试]
end
D --> Strategy
Strategy --> E[提高命中率]
C --> F[Token级命中统计]
E --> F
F --> G{命中率 >80%?}
G -->|Yes| H[成本↓90% 延迟<500ms]
G -->|No| I[检查: 前缀一致性 参数固定 上下文长度]
I --> Strategy